文章目录
- 一、如何为图片打标
- 1.1. 打标工具
- 1.1.1. 秋叶中使用的WD1.4
- 1.1.2. 使用BLIP2
- 1.1.3. 用哪一种
- 二、 Lora训练数据的要求
- 2.1 图片要求
- 2.2 图片的打标要求
- 三、 Lora的其他问题
- qa1
- qa2
- qa3
- qa4
- qa5
- 四、 对图片的处理细节
- 4.1. 图片尺寸问题
- 4.2. 图片内容选取问题
- 4.3. 什么是一张合适的图?
- 4.3.1. 解决水印问题——inpainting
- 4.3.2. 解决边界的问题——裁剪
- 4.3.3. 解决主体多的问题——删除
- 4.3.4. 解决审美的问题——删除
- 问询、帮助
上篇文谈论了一些基础使用,接下来实验一些更细节的问题。
文章链接:
kohya_ss:
https://qq742971636.blog.csdn.net/article/details/138135484
秋叶包基础:
https://qq742971636.blog.csdn.net/article/details/138195344
一、如何为图片打标
1.1. 打标工具
1.1.1. 秋叶中使用的WD1.4
一种词汇打标器,原始训练数据应该是来源于Danbooru 图像, Danbooru 就类似于分类,表述图中有的元素单词,这种倾向于是一个一个的单词(tag)来打标图片。
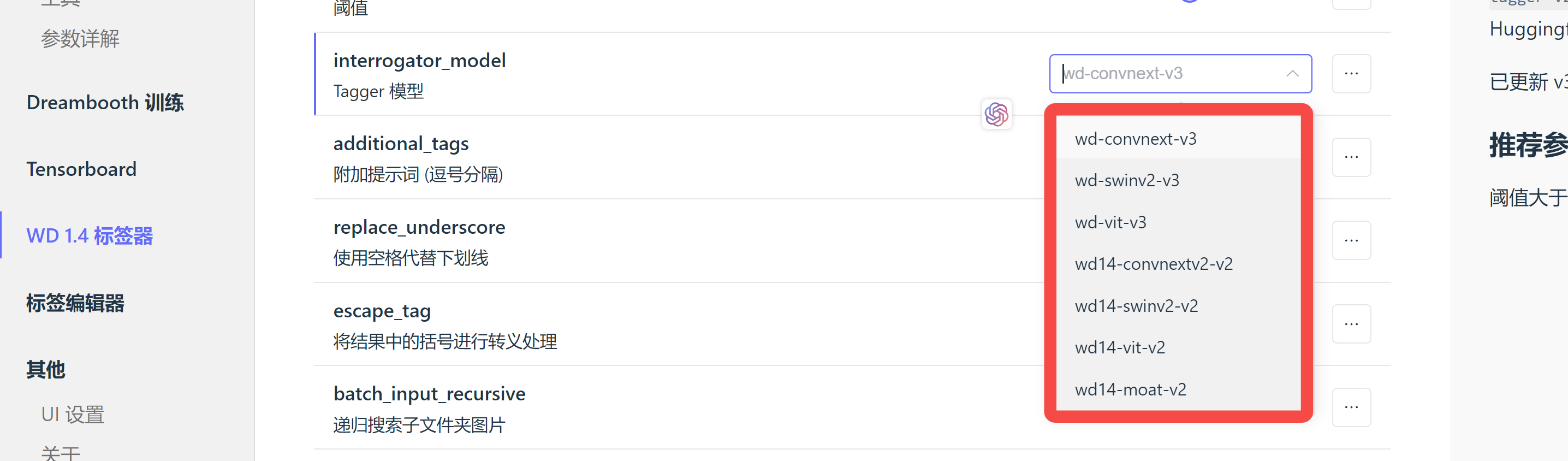
图片打标结果展示如下,一行是一个图片的打标:
solo, monochrome, 1girl, portrait, greyscale, short hair, realistic, traditional media, lips, smile
no humans, monochrome, greyscale, traditional media
1.1.2. 使用BLIP2
BLIP2,这个在kohya_ss中有可视化界面,或者使用程序:
https://huggingface.co/Salesforce/blip2-opt-2.7b
BLIP2的提示语更倾向于是一个短语短句子。
1.1.3. 用哪一种
都差不多,最终都会被CLIP转为嵌入量,只要打标准确达意就好。
二、 Lora训练数据的要求
参考资料:https://zhuanlan.zhihu.com/p/676456908
2.1 图片要求
数量我觉得质量越好、数量越多肯定是最好的。
分辨率适中,勿收集极小图像。
数据集需要统一的主题和风格的内容,图片不宜有复杂背景以及其他无关人物。
图像人物尽量多角度,多表情,多姿势。
凸显面部的图像数量比例稍微大点,全身照的图片数量比例稍微小点。
堆糖:https://www.duitang.com
花瓣:https://huaban.com
pinterest:https://www.pinterest.com
通常,准备数百张图像是理想的(图像数量太少会导致类别图像无法被归纳,特征也不会被学习)。
如果要使用生成的图像,生成图像的大小通常应与训练分辨率(更准确地说,是bucket的分辨率,见下文)相匹配。
2.2 图片的打标要求
如果想要用文字自由控制头发是什么颜色,那么tag中对头发颜色的描述就可以保留。
如果是某个特定的人物ID或者画风,不想要文字控制,想要Lora直接就有效果,那么就需要删除这种描述文字。

三、 Lora的其他问题
qa1
为什么lora有附加提示词?:如之前的概念,附加提示词是为了更好触发Lora功能,如果在后续Lora使用中,加上这个附加提示词去生图,那么就嘎嘎被控出Lora风格,附加提示词最好整点与众不同的词。
qa2
lora训练多少轮合适?:10轮,20轮。看到还有200轮的,loss收敛就好。
qa3
Lora模型的不同之处:网络结构(LoRA/LoCon/LoHa/DyLoRA)?:详细看秋叶包的解释。
qa4
Lora的正则化数据,这种训练数据可以用模型生成或者自己找,比如画风Lora训练中,只想生成卡通人物,那么正则数据就可以选真实人物。
qa5
你为什么会觉得BLIP2的标记更好?
WD1.4的打标是一些tag词,比如我训练的素描风格数据,WD1.4给的tag词里有很多相同的词,比如“monochrome, greyscale, traditional media ”,这些词导致了在后续我使用Lora生图过程中,我需要加这种描述词才能很好地触发Lora风格。而BLIP2的标记只会描述物体内容,就不至于出现这种问题。
只能说,各有长处,每个标记txt文件或许要审查一下更好,偷懒地话用BLIP2或许可以更懒一点。
四、 对图片的处理细节
比如我要训练SDXL的Lora,这种Lora可以将图片改为素描风格,我需要什么样的图片?我应该如何处理图片?哪种图片适合?
4.1. 图片尺寸问题
我需要的是高清图,要有足够的细节。SDXL本身是1024*1024的适应,所以我找的图不能太小,最小也应该有个768的大小。这一点上,可以借助一些超分算法和美化算法来调整图片尺寸,让图片有足够多的细节。故图片最小边大于512就足够好了,不用苛刻太多。
4.2. 图片内容选取问题
基本概念是,模型学习的是一种映射关系,对于没见过怎么转换的,迁移能力不是很强。比如我训练了中国墨水化的Lora,都是用的一些风景图片训练的,那么用这个Lora去生成人物是很垃圾的。模型见过类似的图片映射,才能聪明起来,这是训练的核心。
基于此,如果我想要的是画风Lora,那么我搞的数据应该尽量是各种各样的数据都来点;如果我想要的是某个人物的样貌Lora,那么最好搞的数据就全是这个人物的图片。
在素描风格中,我找了一些乱七八糟的图,我希望Lora学习到的是一种笔触风格:

4.3. 什么是一张合适的图?
基本原则是,凡是带有干扰的图,我都不会要,我都会修改。我要纯粹表达Lora的意向,图片要纯粹。
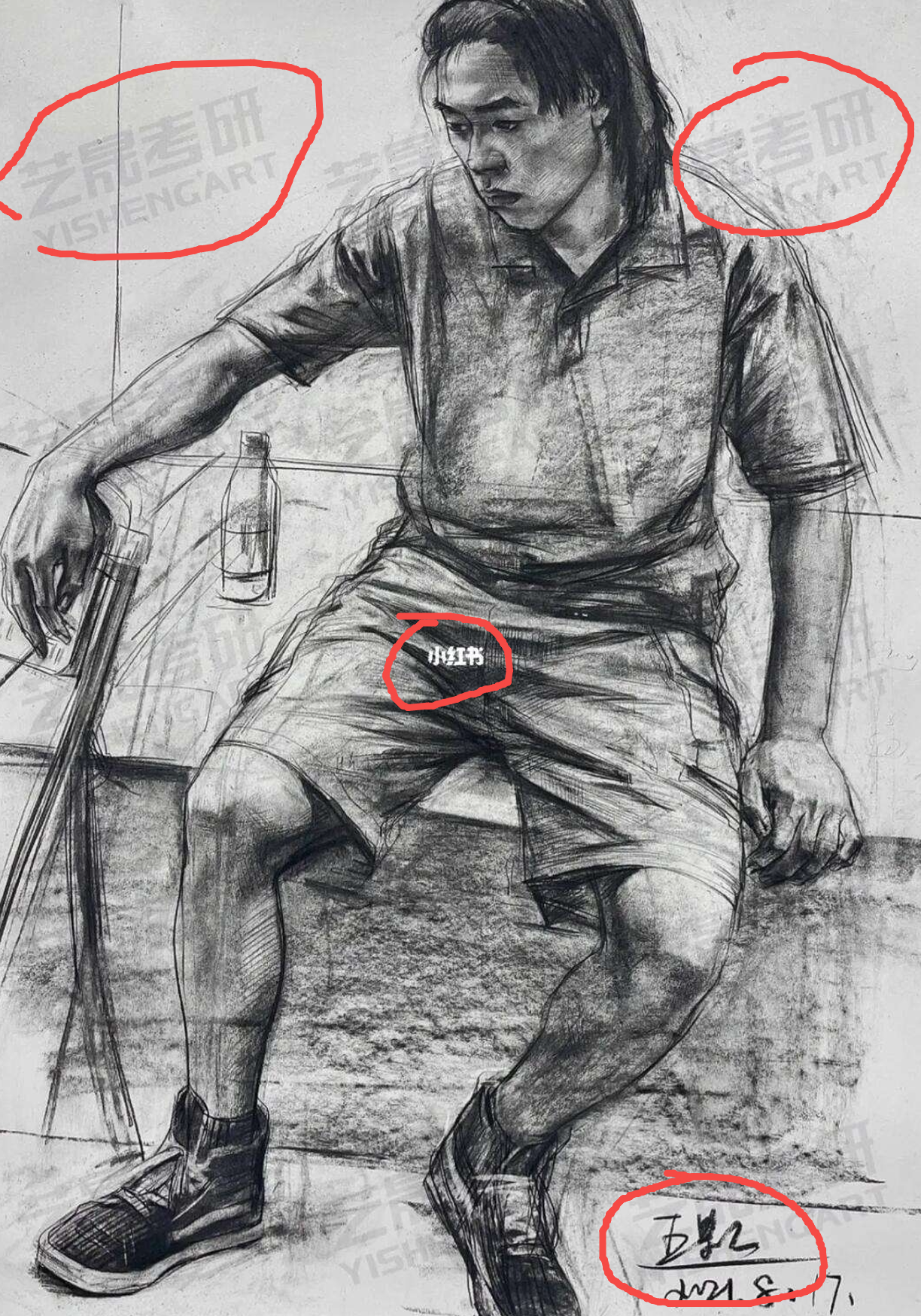
4.3.1. 解决水印问题——inpainting
下图的红圈内都是不想要的图片内容,需要想办法去除:
win10企业版本的图片查看器可以一定程度修改这种情况:
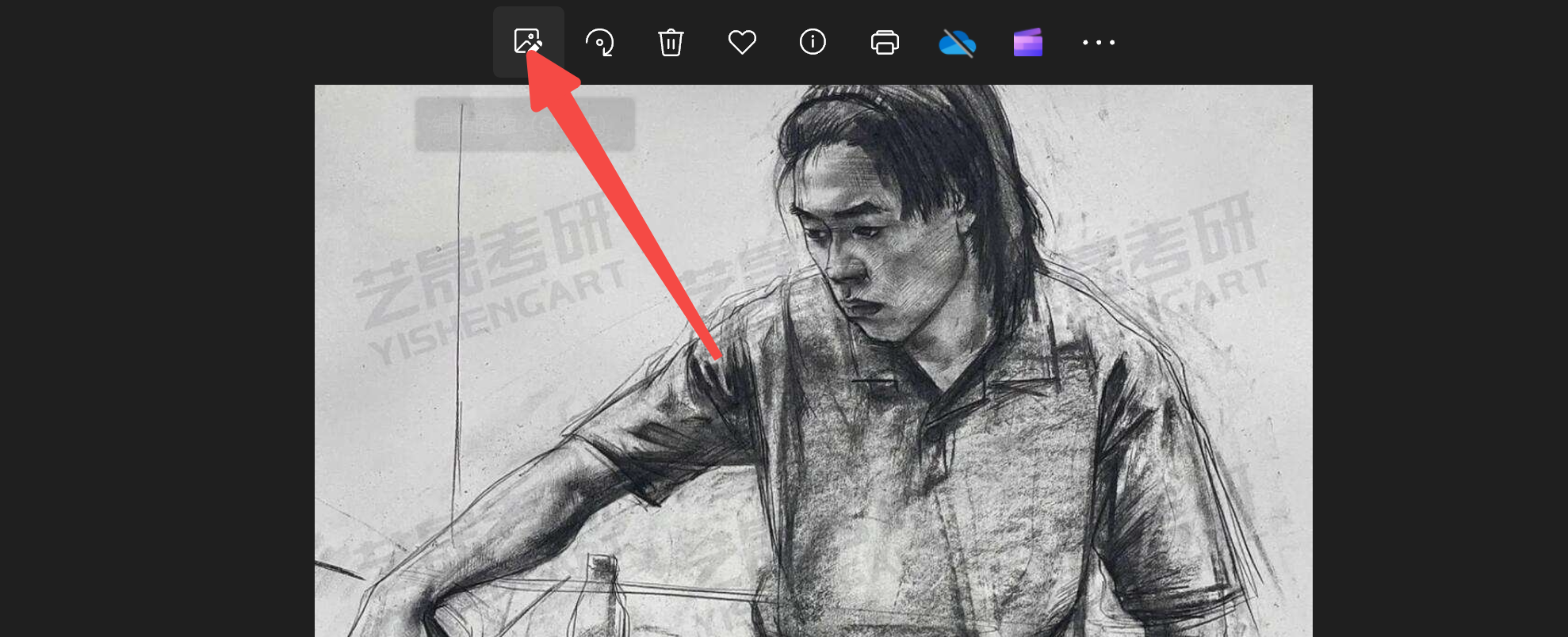
可以看到擦出了很多,有人问下图还有擦不掉的怎么做,当然是直接把这张图扔垃圾桶里。
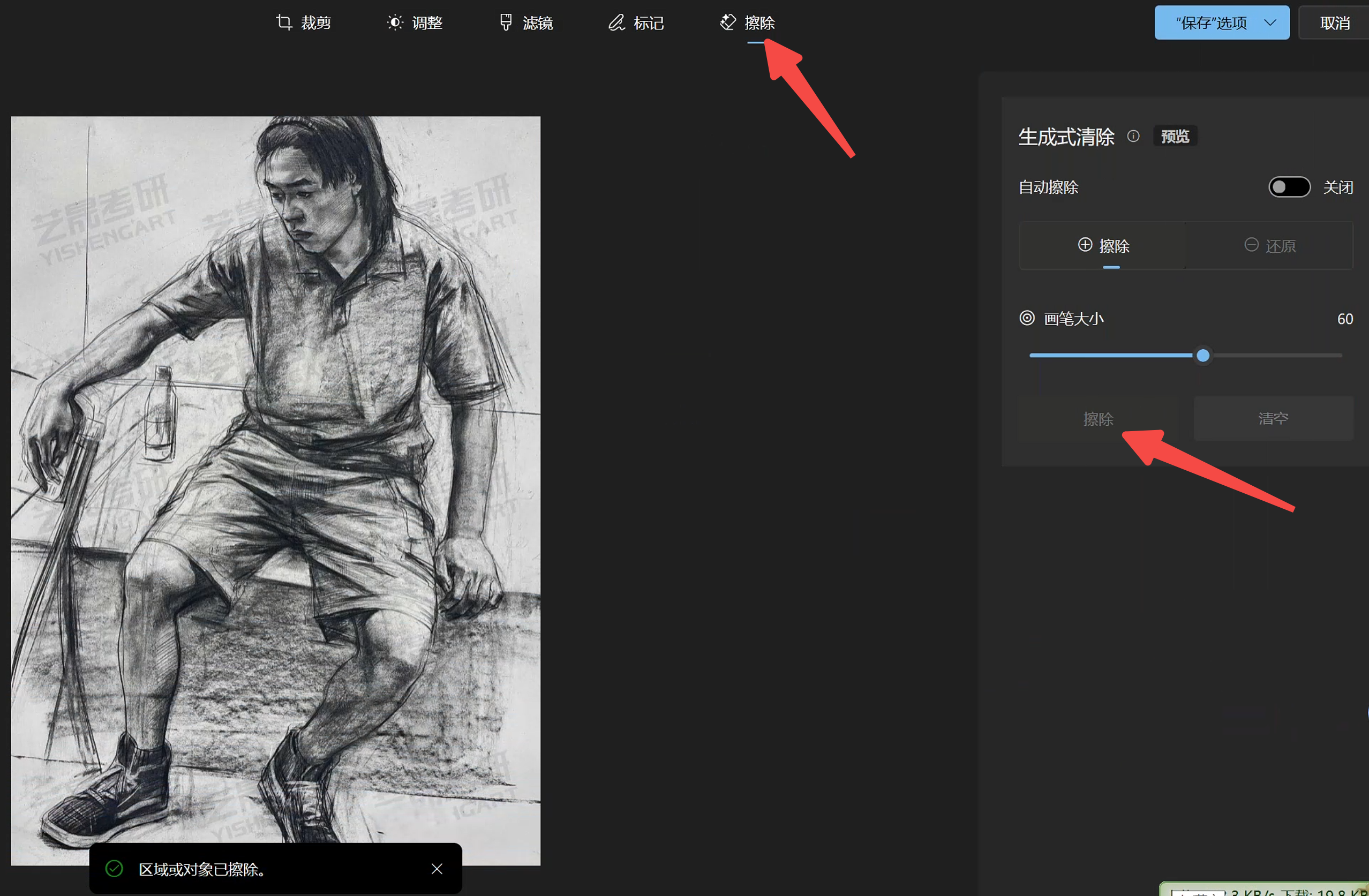
4.3.2. 解决边界的问题——裁剪
人物或者画风的Lora训练都需要遵循“图片要纯粹”。
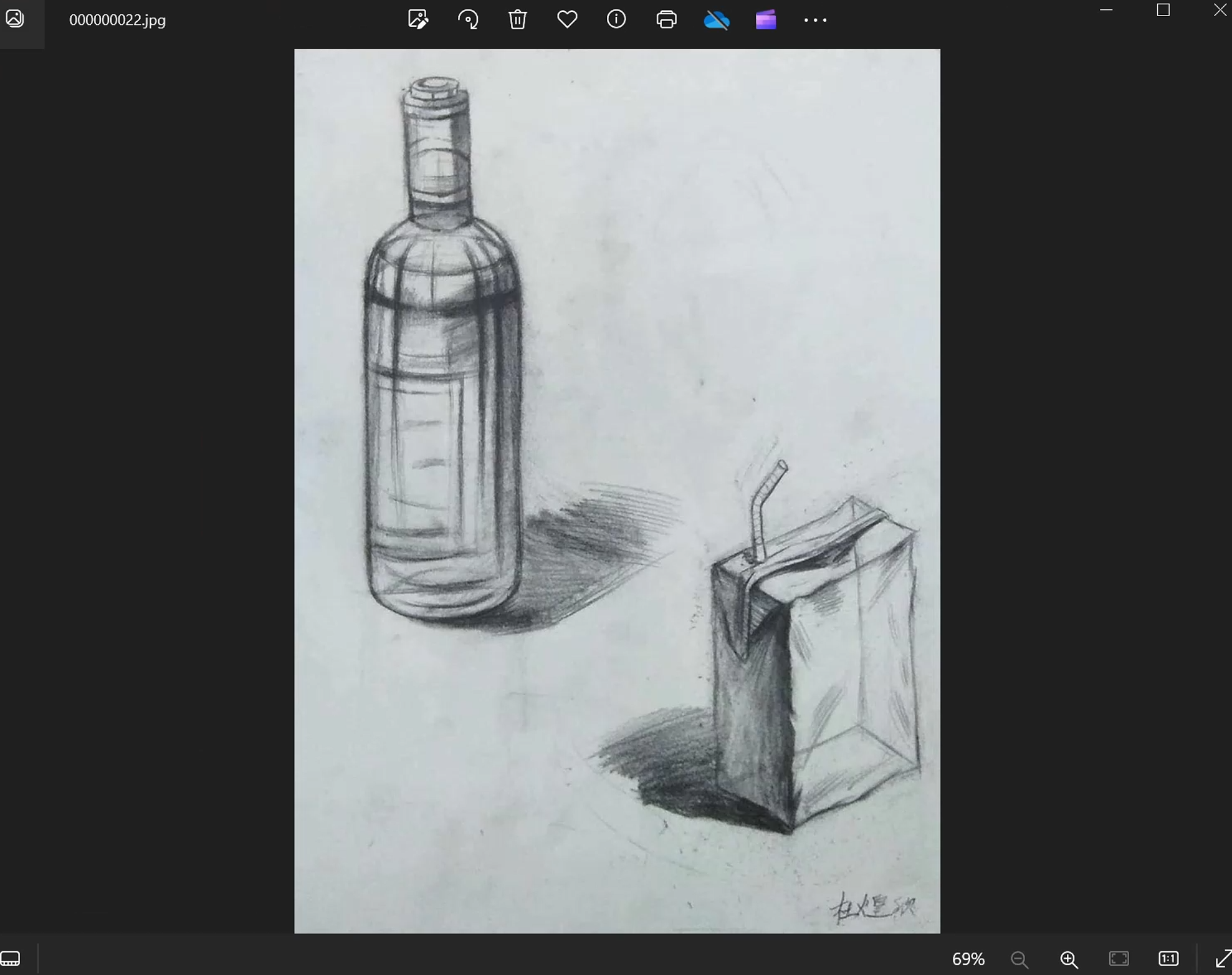
比如画风中这张图的边界其实是一个很差的点,我们绝对不想要Lora指导生图出来的图中有这种难看的边界:

裁剪掉即可:
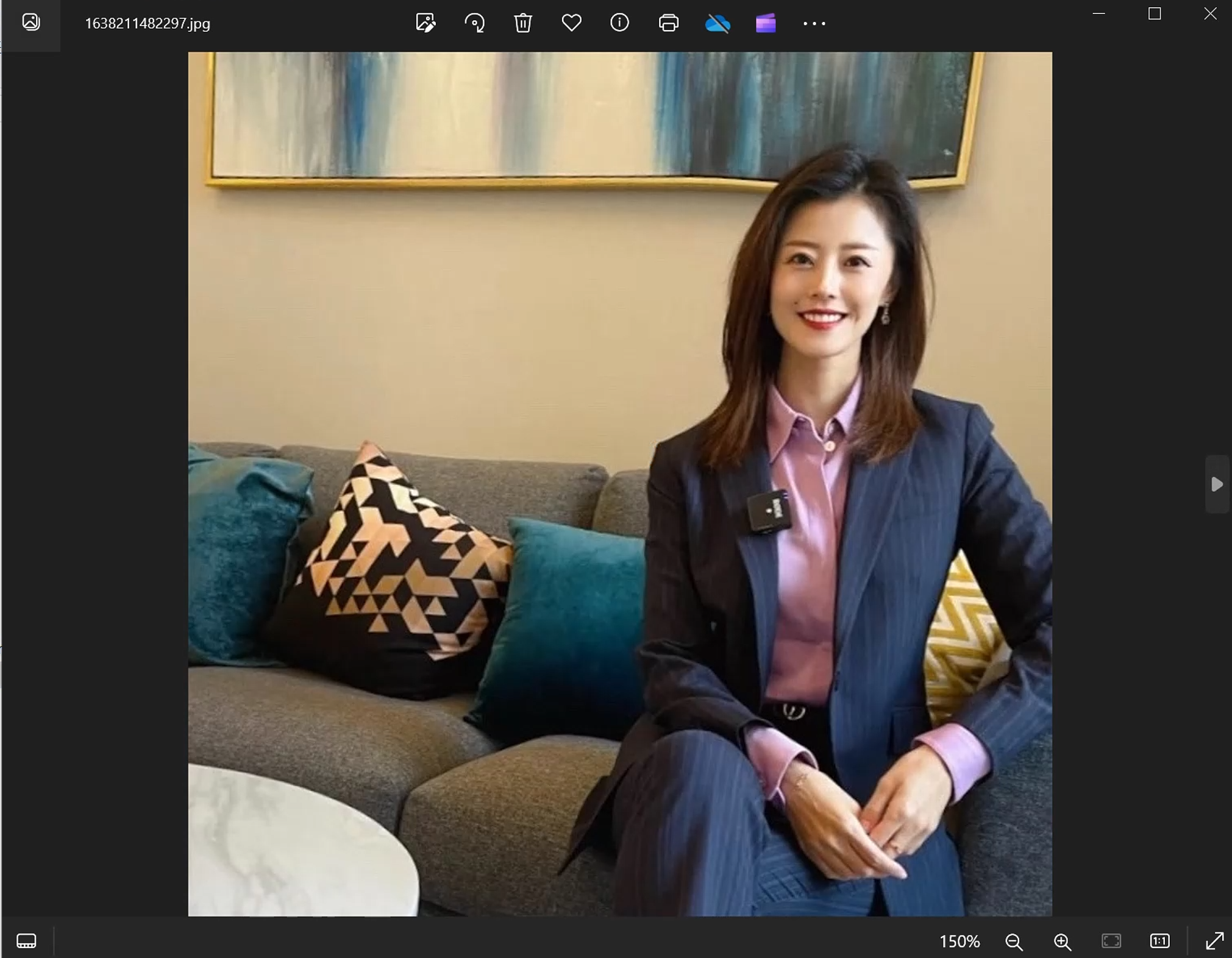
人物Lora训练也有类似的情况,比如这张图,如果是人物Lora,就需要裁剪这张图,因为要突出纯粹的核心内容。
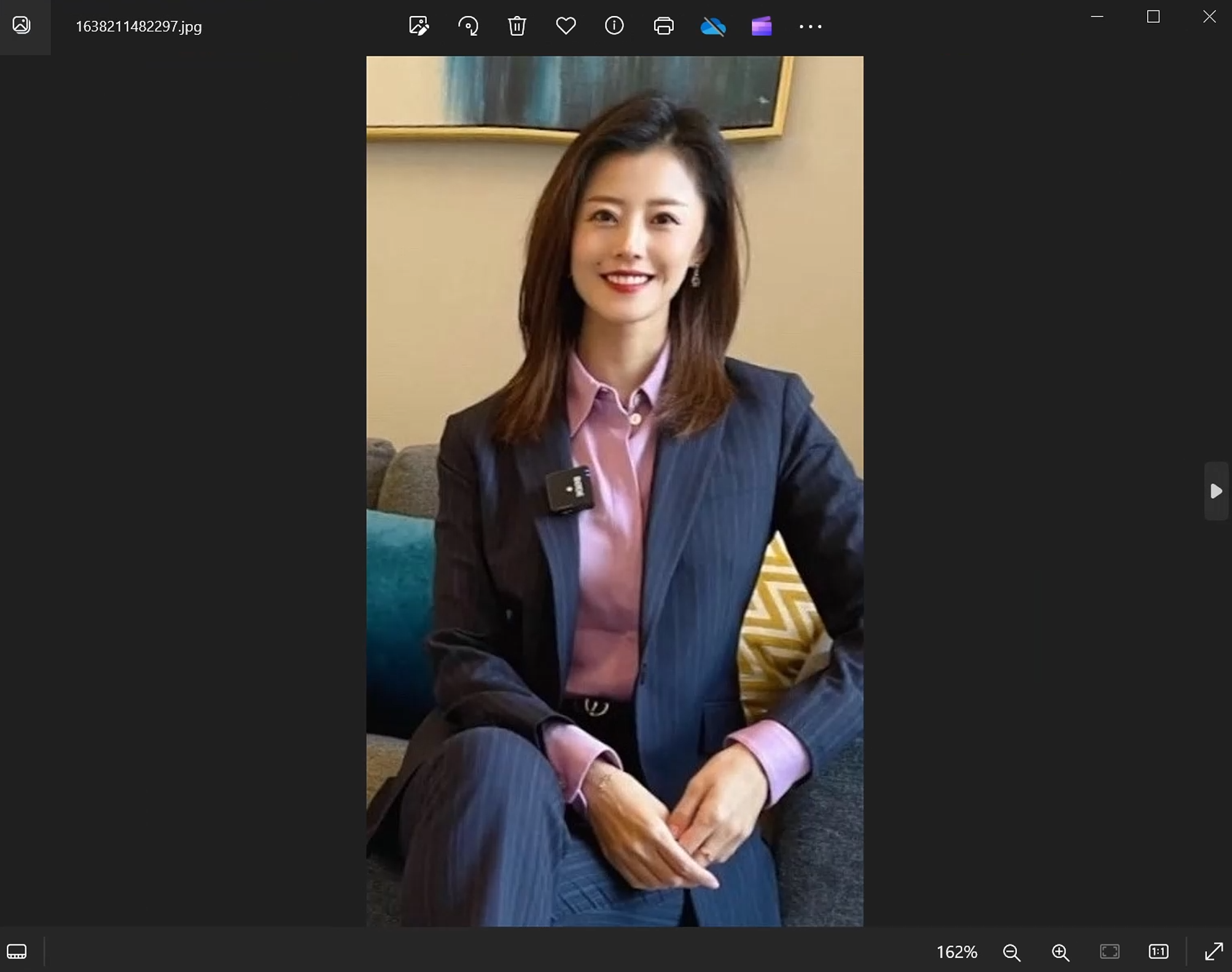
裁剪后是这样的图才行,甚至不想绘制手,也可以把下半身裁剪一些,毕竟Lora那么傻,这么复杂的腿部姿势构图它可能学不会。
4.3.3. 解决主体多的问题——删除
训练素描风格,下面这个图不合适,主体太多,提示词tag很难形成映射。类似地人物Lora也是一样的道理,不要乱七八糟的无关人物干扰最好,否则就删除那张图。

4.3.4. 解决审美的问题——删除
训练素描风格,下面这个图不合适,需要删除。原因在于太丑,我不希望Lora指导绘图绘制出来这么拙略的出图。Lora只是一个小孩子,学映射没那么聪明,这种干扰不要当训练数据给进去,不然Lora学不好。
人物Lora也是类似地,人物如果丑,角度不好,就尽量不要用来当训练数据。

问询、帮助
你如果需要帮助,请看这里:
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2